Yes, Having Stars Matters In October

I’ve been doing a lot of looking at depth charts this week. All of us FanGraphs writers have – these positional power rankings don’t write themselves. When you look at the majors through this lens, you’ll naturally do a lot of thinking about floor and ceiling. The Yankees are playing who at third base? The Brewers are getting how much WAR by avoiding weak spots? The Red Sox have that many outfielders?
I’ve written some team overviews this winter. In them, I make the following claim: “Building a team that outperforms opponents on the strength of its 15th to 26th best players being far superior to their counterparts on other clubs might help in the dog days of August, when everyone’s playing their depth guys and cobbling together a rotation, but that won’t fly in October.” The converse of that claim – that stars matter disproportionately in October – is part and parcel of this depth argument. But is that true?
Some might say that the best time to answer this question is when the playoffs are just around the corner. I’d counter that those people haven’t just spent seven hours staring at a pile of acceptable-but-not-overwhelming third base and starting pitcher options and trying to write something about each one. So in the spirit of doing anything other than looking at power rankings, I decided to test out this assumption.
First things first: I settled on some definitions. I broke my data up into two parts: 1995-2011, the one-wild-card era, and 2012-present, the many-wild-cards era. I borrowed Dan Szymborski’s method for evaluating “what matters” when it comes to playoff roster configuration.
Dan’s plan is delightfully straightforward. First, take a list of playoff teams, playoff games, playoff results, and regular-season statistics for those playoff teams. If you’re trying to determine whether a given regular-season “thing” matters, you just run two regressions: one that tries to predict the outcome of playoff games using regular-season Pythagorean record and home-field advantage, and another that tries to predict those games using Pythag, home-field, and your selected “thing.” If adding your thing makes the predictions better, hooray! If it doesn’t, it’s back to the drawing board. He used an ROC curve, which is perfect for these purposes: It’s good at testing whether an effect exists more so than how good your model is.
Dan used his method to look into a lot of factors you’ll hear about on playoff broadcasts: bullpen strength, home run reliance, contact rate, second-half record, September record, playoff experience, and so on. He found a whole lot of nothing. I repeated his study with a few extra years of data and also found a whole lot of nothing. Then I started adding new stuff – and splitting by era, which deserves its own explanation.
Starting in 2012, MLB expanded the number of teams that qualified for the playoffs, first to 10 and eventually to 12. In my estimation, the composition of the postseason field has changed meaningfully in the expanded playoff era. For one thing, it’s easier to make it. There are just more spots now, which lowers the bar necessary to get in. A team with average players across the board was far less likely to make it into the playoffs in 1998 as opposed to in 2025. It’s just math; far more teams make the playoffs today.
At the same time, teams don’t distribute playing time the way they used to. It’s most notable on the pitching side, where an increasingly broad group of pitchers each takes a decreasingly large innings share. It’s true on the hitting side to a lesser degree; more rest days, more platoons, more focus on load management and surviving the season-long grind. Meanwhile, teams are treating the playoffs as their own paradigm: quicker hooks on marginal starters, higher-leverage bullpen usage, and the best position players in the lineup every game.
I decided that the right way to handle this dataset was by splitting it in two. Conveniently, there are a similar number of seasons on each side: 17 seasons with eight teams in the playoffs, and 13 (after excluding 2020) with 10 or more teams reaching postseason play. I’m open to the argument that the change from 10 to 12 playoff teams should further stratify the data, but that would be slicing things too thinly, with only four seasons under the latest rules.
Dan’s base method – regular-season Pythagorean record plus home-field advantage – was far more effective at predicting the winner of games in the 1995-2011 era. Here’s the ROC curve for using Pythagorean and home-field to predict playoff winners in those years:
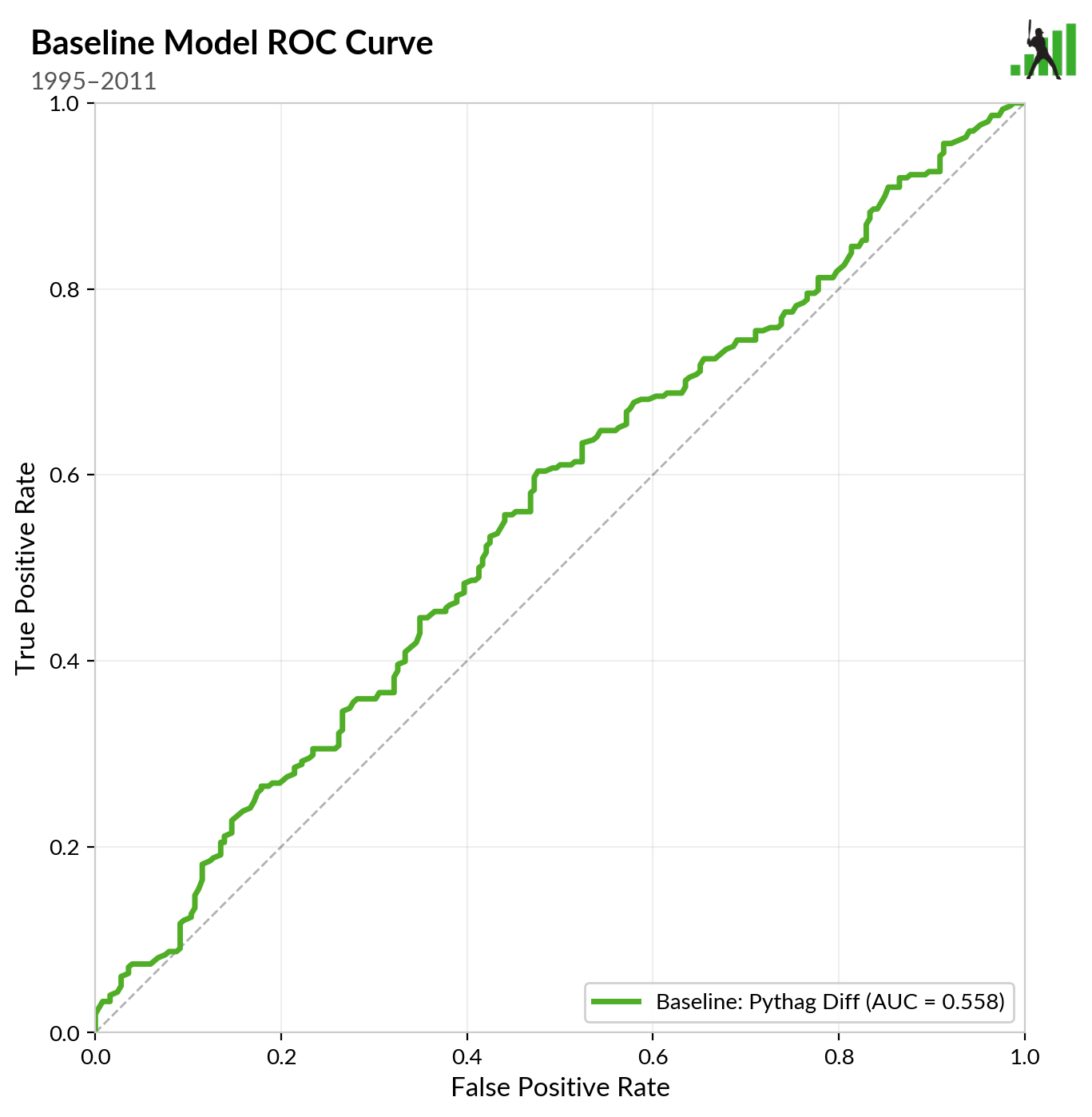
Dan picked these graphs because they’re easy to intuit visually. The more area below the line, the better: You want it to go up and to the left of the diagonal, essentially. This isn’t a great fit, but the truth of the matter is, predicting the winner of baseball games is an inexact science.
That was 1995-2011. Here’s 2012-2025:
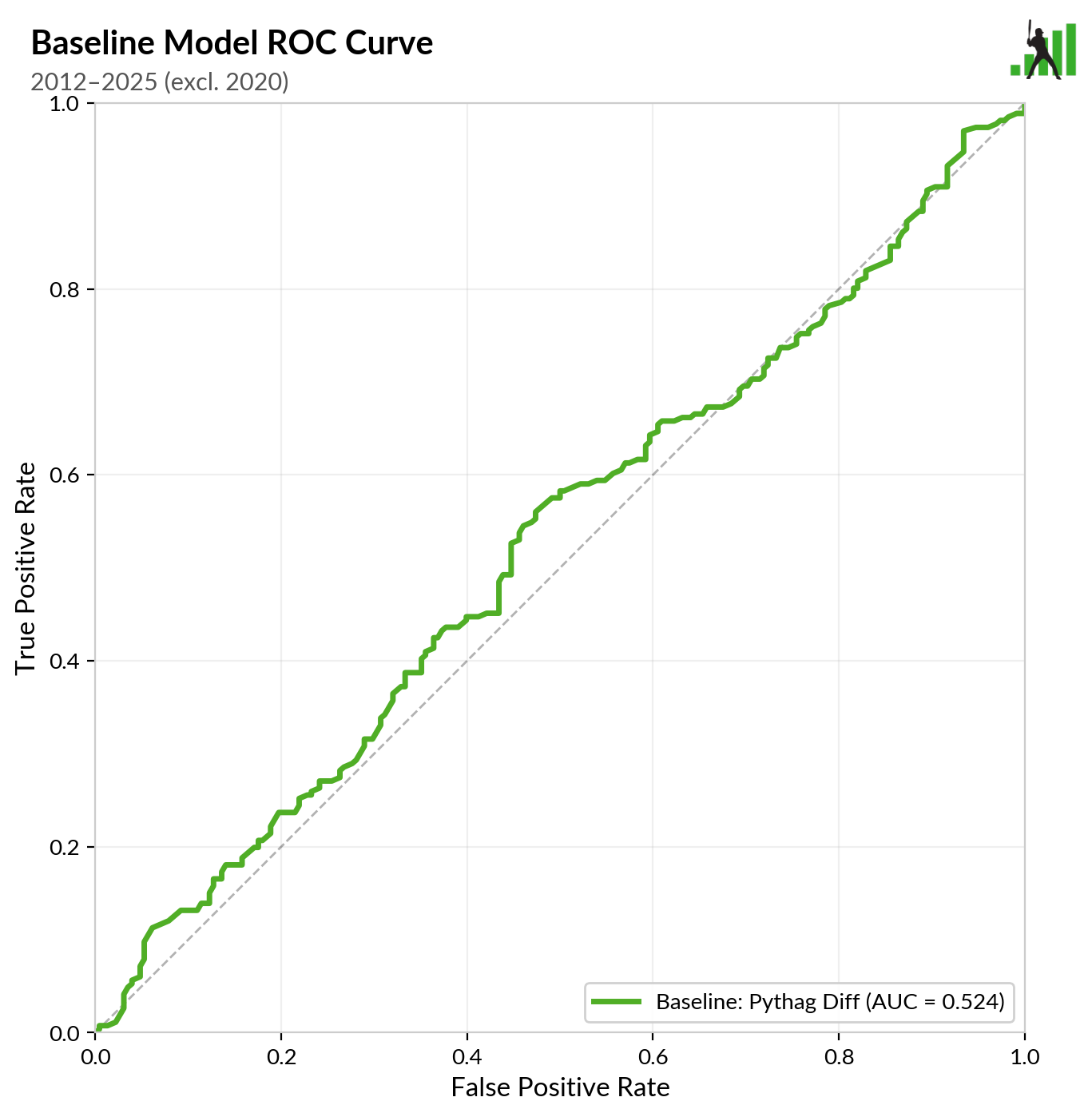
In other words, using Pythagorean expectation to predict the winner of playoff games isn’t working as well as it used to. This makes sense to me, though I can’t point to a smoking gun in the data. Teams treat the regular season differently than the playoffs. There’s no particular reason that the formula that turns regular-season run scoring into an estimation of team talent has to work perfectly for out-of-sample games. It’s a regression that assumes every run scored by a team is equally indicative of its talent. We know that’s not quite true – it’s just an abstraction of reality we’re willing to accept. It’s not shocking that Pythag might be an imperfect reflection of baseball, because it was literally designed as an imperfect reflection of baseball. It still works fairly well, and it still captures a lot about what’s going on, but the linkages don’t seem to be as clean anymore.
Now we get to the interesting part. I gave the model a new piece of information – the WAR accrued by each team’s top five players during the regular season. I asked it to predict the outcome of each game with that new information in hand and then compared it to the Pythag-and-home-field “baseline” version. I’ve drawn the baseline curve in gray and the curve that uses knowledge about each team’s best five players in green:
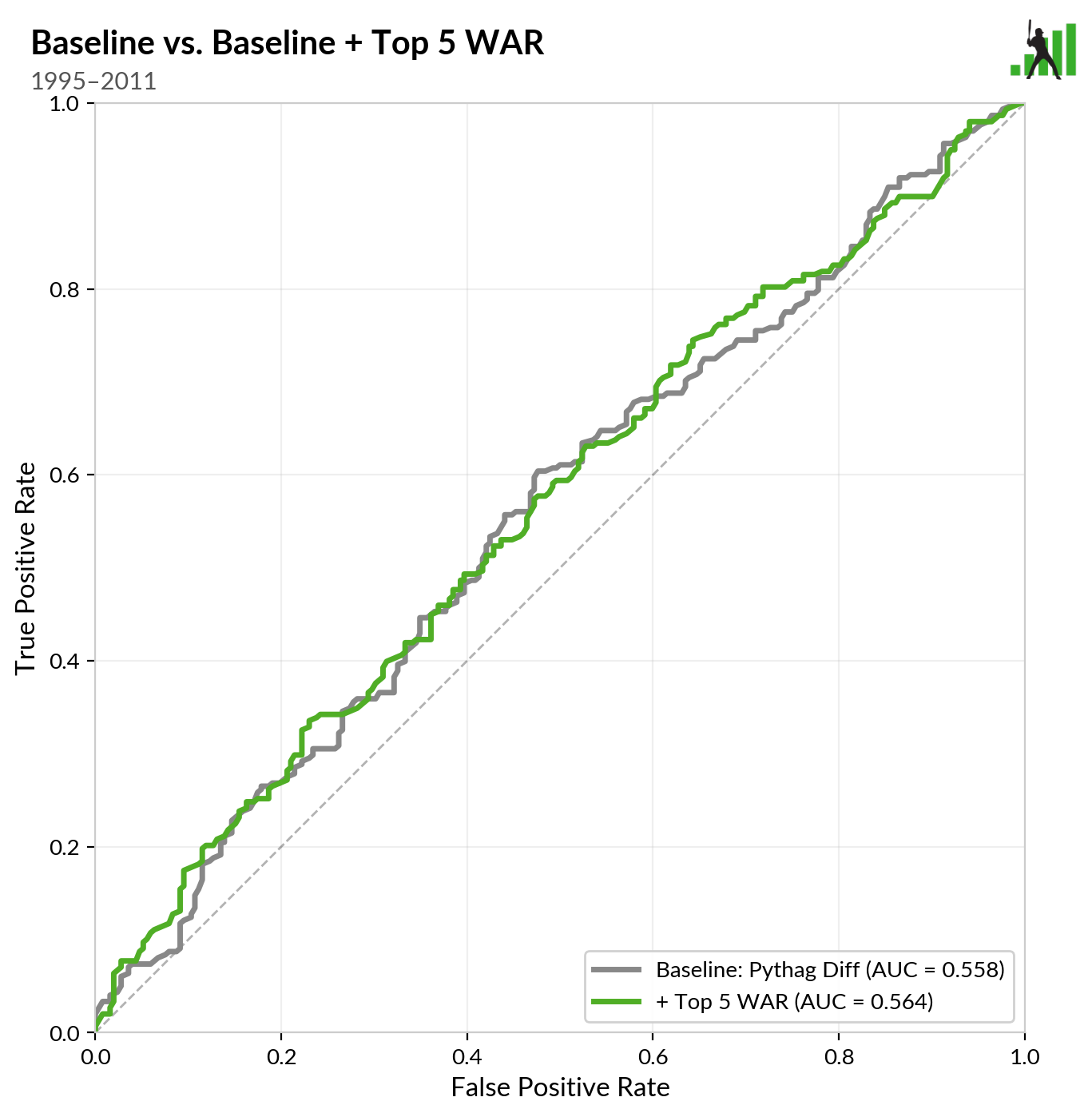
In the 1995-2011 era, the baseline model performed well enough that adding an additional feature didn’t help much. The ROC curves are basically the same – the AUC value you see reported there is the area under the curve. But the same hasn’t been true in the expanded playoff era:
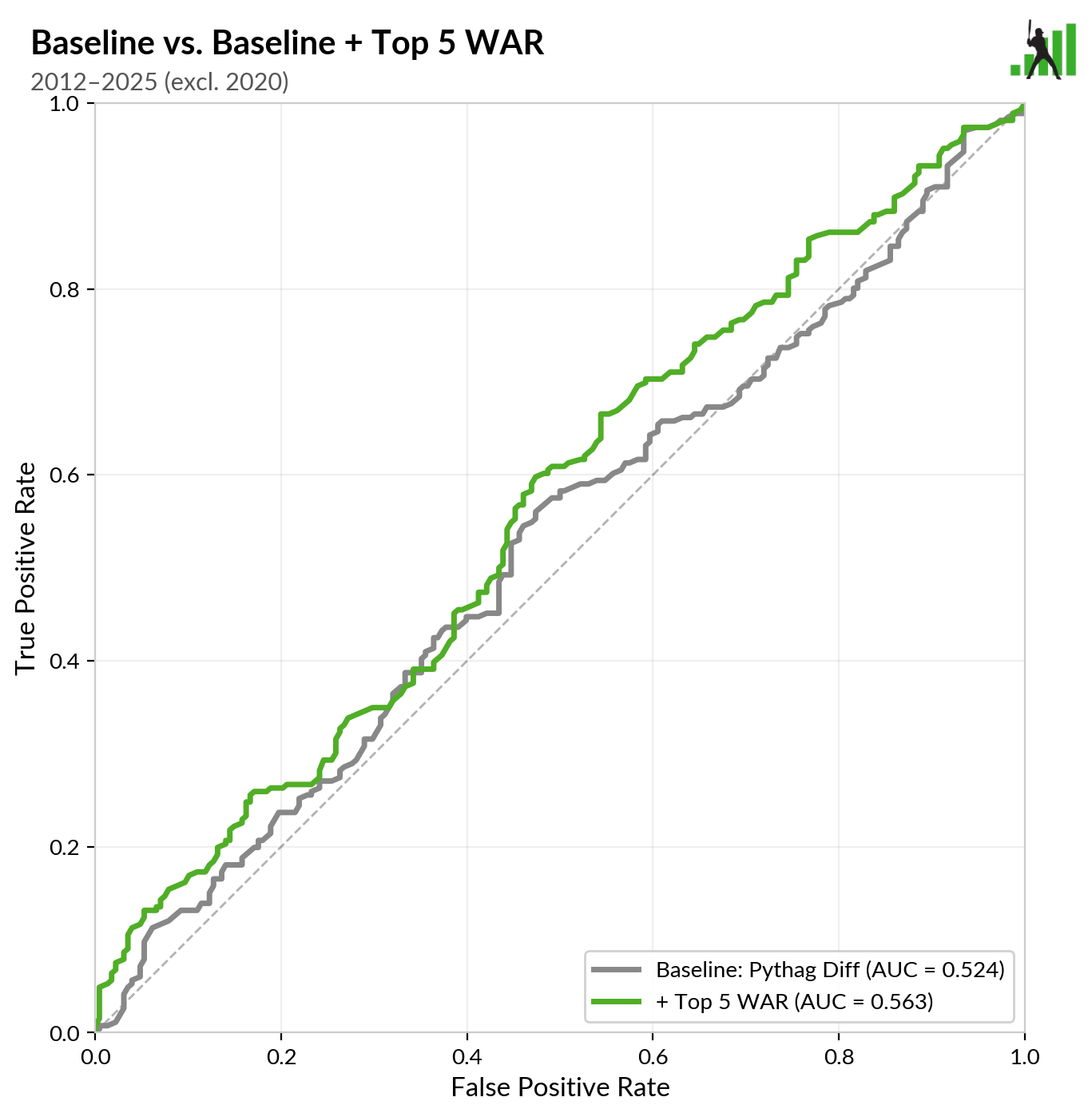
My plain-English interpretation of the data is that while knowing how many runs a team scored and allowed explains some of how that team will perform in the playoffs, it’s explaining less than ever, and how good its best players are seems to add some relevant information. That information has never hurt; it’s just more necessary than it was before when it comes to predicting how a team will do in the playoffs.
Honestly, this makes sense if you stop and think about it. I ran a common sense test to confirm what I think is going on. I took the share of playing time accrued by each player in the playoffs and then forced regular-season playing time to mirror those exact fractions. In other words, if a team’s rotation shortened from five to four pitchers in the playoffs, I redid its regular-season numbers assuming that playing time distribution. I kept per-plate appearance and per-inning statistics constant and allocated 100% of the team’s full regular-season playing time.
In the 2025 regular season, the Brewers racked up an impressive 46.8 WAR. The Dodgers were hardly better, checking in at 49.8 WAR. But when these two teams entered the playoffs, something changed. The Brewers played a squad that, over 162 games, would have produced an estimated 53.1 WAR. They cut out a few part-time backups, redid the bullpen, and generally improved around the margins. The Dodgers played a squad that would have accumulated 67.5 WAR over a full season. They remade their rotation almost completely and played their best hitters more. The Dodgers and Brewers had very similar run differentials in the regular season. But those squads weren’t the ones who played in the postseason, and the Dodgers had another gear available.
Is that exactly the same as measuring the WAR of only the top five players on a team? No, but it’s certainly correlated. And as a supporting effect, I tried some less-severe slices: WAR of the top 10 players on a squad, WAR of the top 15 players on a squad, an HHI coefficient, and various other measures of team composition. The more players I threw into the mix, the weaker the effect got. Using the WAR of the top 10 players still gave me a statistically significant result, but only barely so. Moving to the top 15 meant no significance. Measuring only the sixth to 15th players added no predictive power at all. In other words, knowing something about the best players on a team has been helpful for making playoff predictions in the double-digit-playoff-team era.
It’s worth mentioning that knowing this effect exists isn’t the same as having a model that captures that effect well. The AUC/ROC method measures how well a model ranks outcomes ordinally, not how confidently it predicts those outcomes. It doesn’t test calibration, merely the ability to distinguish broadly regardless of calibration. And while these values are clearly better than chance, they’re nowhere near providing actionable single-game predictions. There is a structural pattern across 500 or so games in the multiple wild-card era that suggests that knowing a team’s best players gives you additional valuable information about that team’s chances, and that teams with better stars outperform in the playoffs relative to what you’d expect if you only looked at run differential in the regular season. I can’t say more than that – but I think that’s a strong conclusion nonetheless.
Ben is a writer at FanGraphs. He can be found on Bluesky @benclemens.
This is a theory I always had behind the A’s playoff failures in their last two runs from 2012-2014 and 2018-2020.
They were solid teams with few weak spots but fewer star level performers compared to other playoff teams.
That second window had Chapman, Semien, and Olson. Less famous than some others, but not a bad core of star players. Aside from the Dodgers, who are just loaded top to bottom, if you look at the winners of the past several World Series, anecdotally it seems like a mixed bag. Obviously if you look at two teams with a bunch of average to good first division starters and then one has a couple superstars, that team will be better. But there aren’t a lot of actual stars and scrubs World Series winners.
Here’s a loaded question- Does the fact 2 of those 3 (Semien, Chapman) got an unusually large portion of their WAR/value by defense mean anything?
Trying to think it threw logically & I can see a case that differences in defensive value may mean less in the postseason- No trying guys at new positions, more defensive subs near the end of games for those that aren’t as good, the attention/effort level is better for all.
Maybe nothing..but, something that crossed my mind.